1. Analyzing Algorithms and Problems: Principles and Examples
1-4. Searching on Ordered Array 정렬된 배열 탐색
Problem and Strategy A
Problem: array search 배열 탐색
n개의 entry가 담긴 배열 E와 value K가 주어졌을 때, 배열에서 K=E[index]를 찾는다면 인덱스 값을, K를 찾지 못한다면 -1을 결과로 리턴한다.
Strategy A
- input data와 자료구조: 정렬되지 않은 배열
- sequential search(index 0부터 차례로 비교)
Algorithm A
int seqSearch(int []E, int n, int K)
Analysis A
- W(n) = n //worst case
- A(n) = q[(n+1)/2] + (1 - q) //평균 수행시간, q: 성공확률; 1 - q: 실패확률
Better Algorithm / Better Input Data
Optimality A
- F(n) = n //최악의 경우 n번의 연산 필요
- Algorithm A는 Optimal하다.
Strategy B
- input data와 자료구조: 비내림차순으로 정렬된 배열
- 비내림차순: 각각의 원소가 바로 앞에 있는 원소보다 크거나 같을 경우
- sequential search(index 0부터 차례로 비교)
Algorithm B
int seqSearch(int []E, int n, int K)
Analysis B
- W(n) = n
- A(n) = q[(n+1)/2] + (1 - q)
- 알고리즘 자체가 변한 게 없기 때문에 worst case와 평균 수행시간은 A와 동일
Optimality B
- entry의 순서가 정렬되어 있다는 사실을 이용하지 않다.
- 알고리즘을 수정해서 추가된 정보를 사용하고 일을 덜 하도록 할 수 있을까?
Strategy C
- input data와 자료구조: 비내림차순으로 정렬된 배열
- sequential search: K보다 큰 entry를 만나자마자 알고리즘은 answer -1을 리턴하며 종료한다.(정렬된 배열이므로 그 뒤로는 K값이 존재할 수 없다. 따라서 뒤 값은 볼 필요 없음)

Algorithm C: Modified Sequential Search
int seqSearchMod(int[] E, int n, int K)
1. int ans, index;
2. ans = -1; // 실패 대비 초기화
3. for (index = 0; index < n; index++)
4. if (K > E[index])
5. continue;
6. if (K < E[index])
7. break; // Done!
8. // K == E[index] 탐색 성공
9. ans = index; // Find it
10. break;
11. return ans;
int []E, int n, int K☞ input

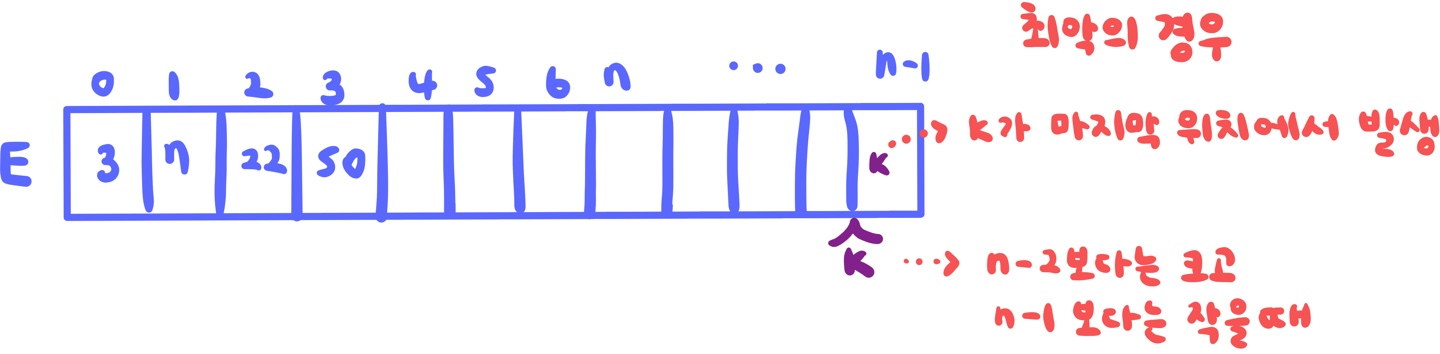
최악의 경우를 가정: K가 E[n-1]에 존재 or K가 배열 내에 존재하지 않음
4. if (K > E[index])
continue; //다음 entry 비교- E[0] ~ E[n-1]까지는 entry 값이 K보다 작음.
- K가 entry들보다 크기 때문에 K값을 찾으면서 n번 이동
- continue 만나면 for문 맨 앞으로 돌아간다.
☞ 비교연산 n회
최악의 경우 (탐색 실패): E[n-2] < K< E[n-1]
6. if (K < E[index])
break; // Done!- E[n-2]보다는 크고 E[n-1]보다는 작을 때, K는 해당 배열에 존재하지 않는다.
- ex. E[n-2] = 88; E[n-1] = 98, K = 80일 때.
- 이 경우 바로 for문을 빠져나간다.
☞ 비교연산 1회
8. // K == E[index] 탐색 성공
9. ans = index; // Find it
10. break;- K == E[n-1]일 때, ans변수에 현재 인덱스 값을 대입하고 for문을 빠져나간다.
11. return ans;- 탐색 성공한 경우 answer 변수에 대입된 인덱스 값을 리턴하고, 탐색에 실패한 경우 초기값 -1을 그대로 리턴한다.
☞ total: n + 1번 비교연산 수행
Analysis C
W(n) = n + 1 ≈ n
Average-Behavior

- Pr(I) : 특정 input I가 발생할 확률
- t(I) : 그때 사용한 Basic Operation 수

- n cases for success:

▷ Pr(I | succ) = index 하나에서 K 발생할 확률. 배열 총 n개이므로 1/n
▷ t(I) = E[0] ~ E[n-1]까지 i+1번의 비교연산
▷ 성공 시 case는 Stratety A, B 동일
- n+1 cases or (gaps) for fail: E[1]…E[n-1]>
gap: 두 entry 사이에 있는 값
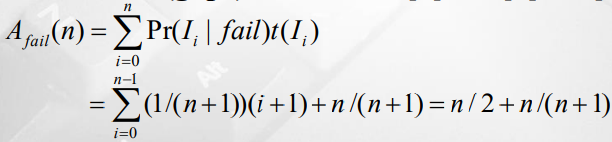
▷ Pr(I | fail) = K 탐색 실패할 확률. K가 어느 gap에 있을지 그 확률을 계산한다고 생각해도 됨. gap이 총 n개 + 맨 뒤 gap 1개. 따라서 최종적으로 1/(n+1)
▷ t(I): 그때 basic operation 수
1. E[0] ~ E[n-1]까지 i+1번의 비교연산
2. 맨 뒤 gap은 n번의 연산이 필요(K < entry이면 K는 왼쪽 gap에 속하고 K > entry이면 K는 오른쪽 gap에 속한다.)

A(n) = q (1+n)/2 + (1-q) (n /(n+1) + n/2) ≈ n/2
자료 출처
Computer Algorithms
(Sara Baase, Allen Van Gelder저, Addison Wesley, 2000)
'Computer Science > 알고리즘' 카테고리의 다른 글
| 알고리즘10. Heapsort (0) | 2021.11.11 |
|---|---|
| 알고리즘: Mergesort 합병 정렬 (0) | 2021.11.11 |
| 알고리즘6. Searching on Ordered Array(정렬된 배열 탐색)(2) - binary search(이진탐색) (0) | 2021.10.03 |
| 알고리즘4. 점근적 증가율에 따른 함수 분류 (0) | 2021.09.13 |
| 알고리즘3. 알고리즘과 문제 분석 (0) | 2021.09.07 |
| 알고리즘2. 수학적 배경지식 (0) | 2021.09.02 |